Level 별 prediction task 방법
Question: GNN을 통해 Node Embedding을 얻고 나서 실제 Task는 어떻게 수행할 것인가?
--> 각 레벨 별로 어떤 식으로 task를 수행할 수 있는지 알아보자.
(아래에서는 prediction head를 가지고 어떻게 활용할 수 있는지 알아보는 것이라 할 수 있다.)
| Level | 방법 |
| Node-level | - 노드 임베딩에 웨이트를 곱해서 바로 prediction! |
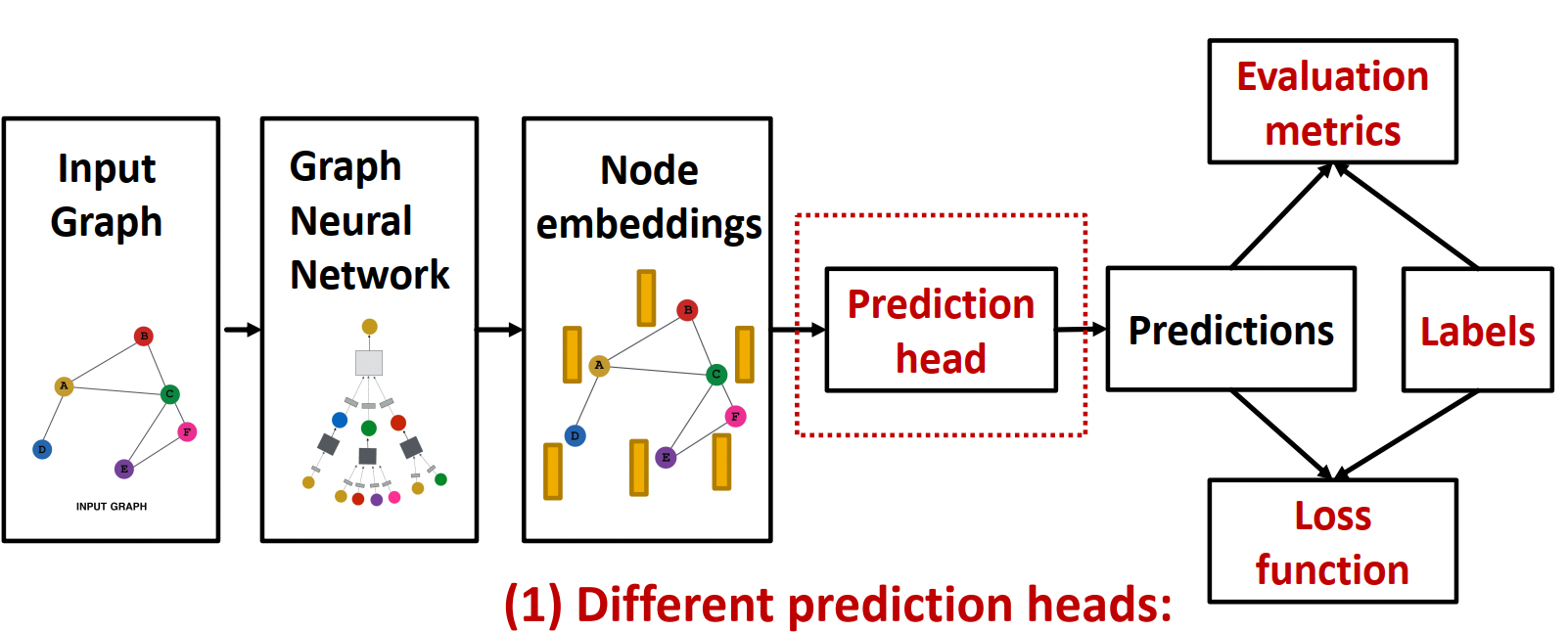
| Edge-level | - 두 노드 임베딩을 concat한 뒤 MLP 적용! - 두 노드 임베딩을 dot-product 1- way: 바로 product 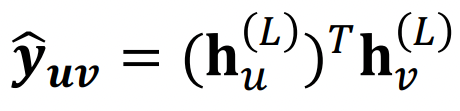 k-way: 가운데 여러개의 Weight를 시도한 뒤 Concat해서 만든다.  |
| Graph-level | 노드 임베딩을 aggregation처럼 모아주는 operator를 활용해서 예측에 사용한다.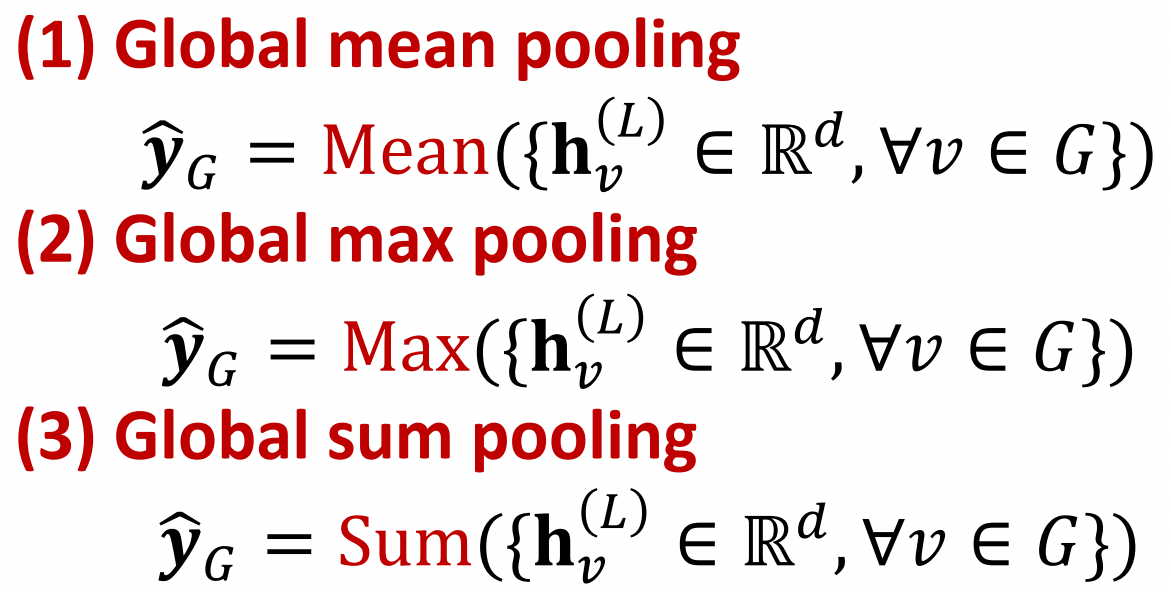 NOTE: 위의 global pooling method들 같은 경우 서로 다른 노드 임베딩이 같은 결과를 나타낼 때도 있기 때문에 다른 방법이 필요하다. 아래 예제에서도 sum pooling을 하게 되면 node feature들의 절대값들이 달라도 결과가 같아지게 되는 문제가 생긴다. 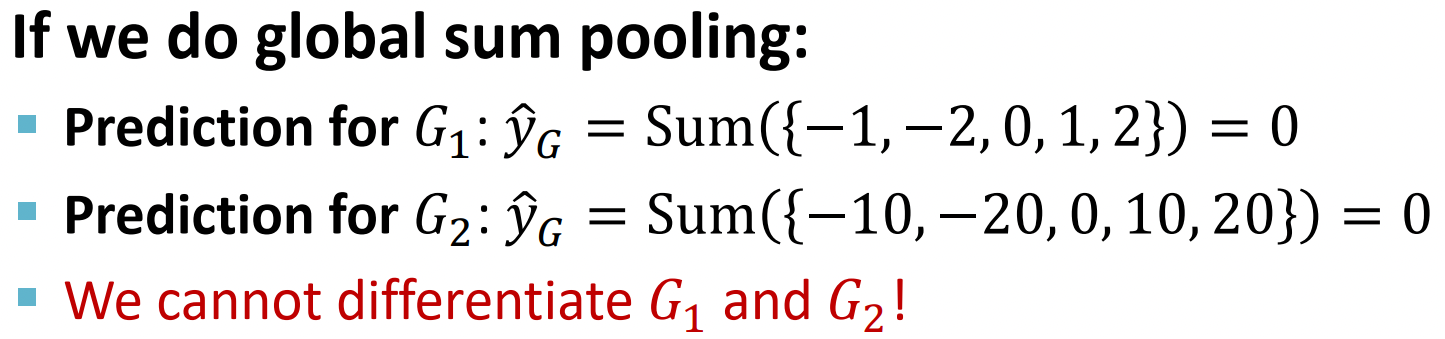 |
DiffPool (Hierarchical Pooling)
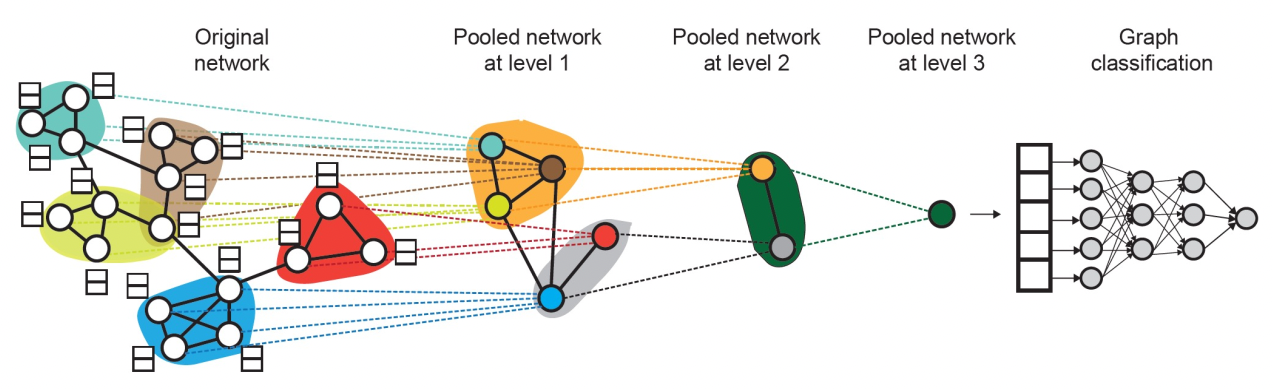
위의 그림처럼 원본 그래프를 점점 더 작은 그래프로 바꾼 다음 graph embedding을 구하게 된다.
각 단계별로
1. 노드 임베딩을 구하고
2. 주어진 노드 임베딩을 가지고 클러스터링을 한뒤
3. 클러스터링 별로 pooling을 적용하여 다음 스테이지를 위한 single node를 만든다.
Supervised Vs Unsupervised Tasks
그래프를 가지고 할 수 있는 task 중에 supervised와 unsupervised가 있다.
아래 표를 보면 알겠지만 unsupervised 같은 경우는 그래프의 구조 자체를 활용한다.
| Supervised | Unsupervised (Self-supervised) |
| label(node, edge, graph level)이 존재한다. 가장 쉬운 task이므로 왠만하면 문제를 이 task들로 변환하여 풀도록 하자! |
label이 존재 하지 않기 때문에 그래프에서 얻을 수 있는 정보를 최대한 활용 - Node level: Node degree, clustering coefficient - Edge level: Link prediction (실제로 존재하는 edge를 숨겼다가 다시 찾아내기) - Graph level: graph statistics를 이용 |
Loss function for supervised learning
- Classification task: Cross entropy loss를 활용한다. (아래 cross entropy는 K개의 data가 있을 때를 의미한다.)
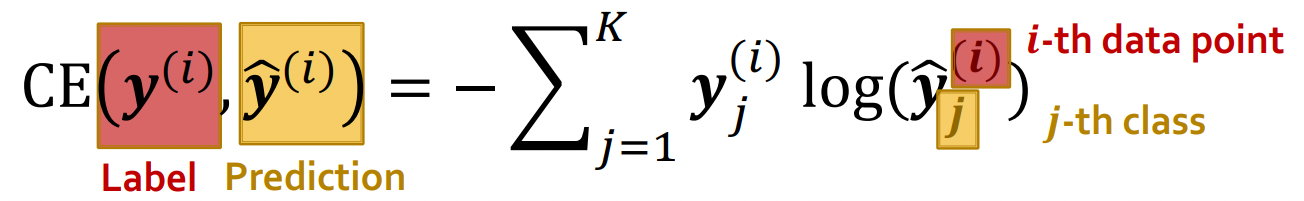
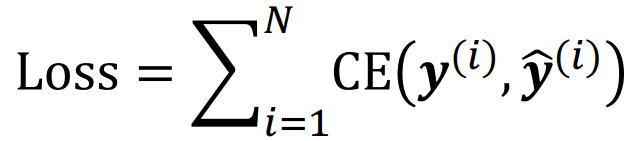
- Regression task: L2 error (Mean Square error)를 활용한다.)
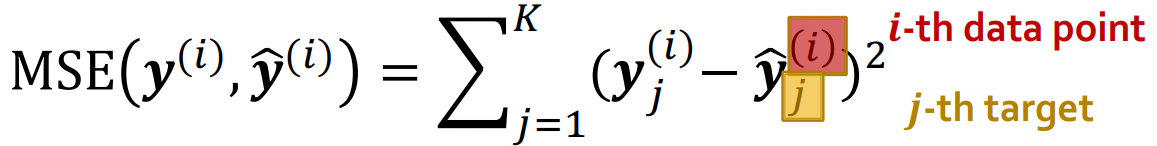
Evaluation Metric
- Classification task
Multi-class classification의 경우
--> accuracy를 측정 전체 중 정확하게 예측한 것은 몇개인가?
Binary classification의 경우
--> Confusion matrix를 활용

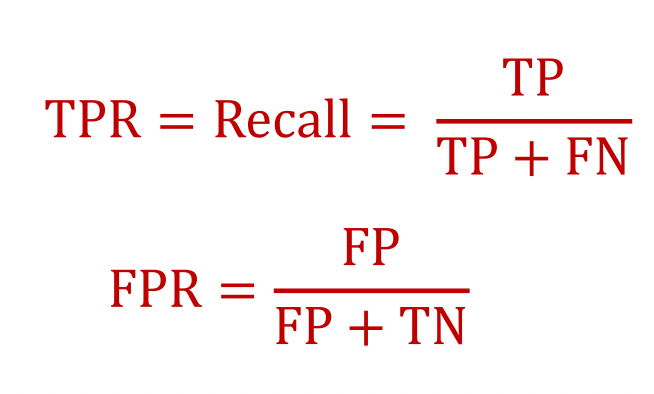
Accuracy: 전체 중 맞춘 것은 무엇인가? (TP + TN) / (TP + TF + FP + FN)
Precision: True라고 예측한 것 중에 진짜 True의 비율(얼마나 오진을 했냐) (TP) / (TP + FP)
Recall: 모든 True들 중 True라고 예측한 것의 비율(얼마나 진짜 True를 빼먹지 않았냐) (TP) / (TP + FN)
어떤걸 예측한다고 했을 때, False의 비율이 굉장히 낫다고 하자.
그러면 무지성으로 True로 예측하면 왠만하면 Accuracy, Precision, Recall이 모두 높게 나올 것이다.
그래서 다음과 같은 개념이 등장한다.
ROC (Receiver operating characteristic) curve and AUC (Area under Curve)
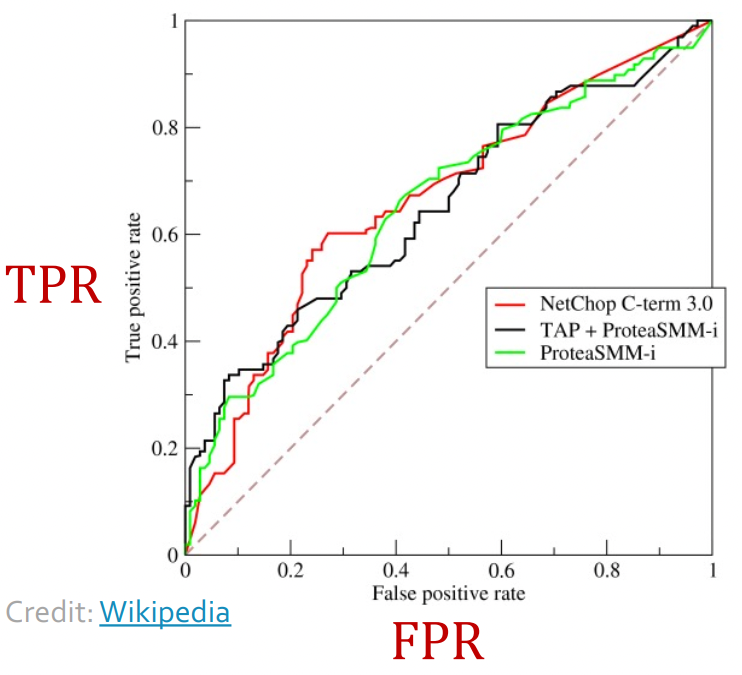
Binary classification에서 threshold를 바꾸면 TPR과 FPR이 바뀌게 된다.
우리의 목표는 FPR이 0이 되고, TPR이 1이 되게 만드는 것이다. (최대한 왼쪽 위)
threshold가 1이면 아무것도 positive가 안될 것이므로 TP=0, FP=0이어서 (FPR,TPR)=(0,0)에 있을 것이고
threshold가 0이면 모든 것이 positive가 될 것이므로 (FPR,TPR)~(1,1)에 있을 것이다.
우리는 최대한 curve 자체도 왼쪽 위로 넓어지기를 원하고 (AUC)
그 중 가장 왼쪽 위에 있는 point를 통해 threshold를 고를 것이다.
- Regression:
Root Mean Square Error(RMSE)
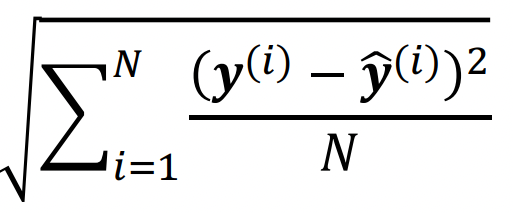
Mean Absolute Error(MAE)

Split data (train, validation, test set)
일단 random하게 split하고 여러번의 학습 결과를 평균을 내야 한다.
그렇다면 어떻게 random하게 split해야 할까?
| Transductive Setting | Inductive Setting |
| (1) original graph 전체를 사용한다. (2) 구한 embedding을 train, validation, test에 모두 수행한다. Node, Edge task만 수행 가능하다. |
(1) Graph를 training, validation, test용으로 쪼갠다. (2) 각 graph셋만 가지고 embedding을 구하고 prediction 한다. Node, Edge, Graph task 수행 가능 |
Link Prediction example
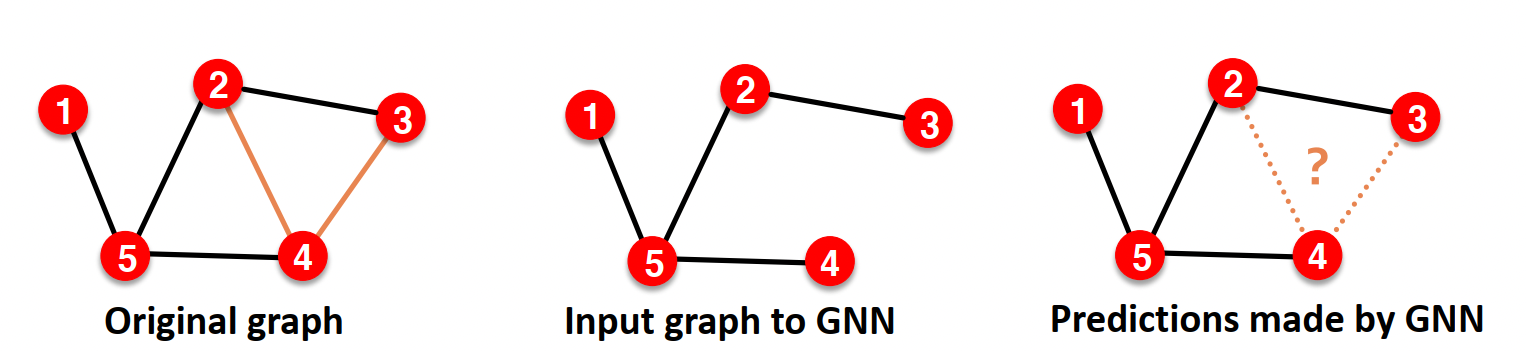

Link prediction에서는 edge를 감춰서 학습에 쓰일 edge는 message passing edge, 실제 존재하는지 맞춰야하는 edge를 supervision edge로 나눈다.
Inductive setting에서는 단순히 그래프를 나눠서 하면 되지만 아래와 같은 Transductive setting은 약간 tricky하다.
(1) Transductive setting에서는 그래프를 세 개로 세트로 나눈 뒤 그 안에서 message passing edge, supervision edge로 나눈다.
(2) Training 단계에서는 Training message passing edge와 Training supervision edge로 학습한다.
(3) Validation 단계에서는 Training message passing edge + training supervision edge로 validation supervision edge를 예측한다.
(4) Test 단계에서는 Training message passing edge + training supervision edge + Validation supervision edge로 test supervision edge를 예측한다.
참고: 원래 Transductive setting이라면 모든 단계에서 전체 graph structure를 이용해야 하기 때문에 모든 edge를 이용해야 하지만 edge 자체가 각 단계에서 prediction의 대상이 되기 때문에 점진적으로 더 넣어주게 되는 것이다.
* feature augmentation
(사실 이 부분은 정작 중요한 부분이 아닌데 8단원 강의의 첫부분에 나온게 이상하긴 하다)
때로는 feature가 부족하거나 아무것도 없을 때는 임의로 feature를 넣기도 한다.
| Feature augmentation 방법 | Constant 1을 집어넣기 | Node ID를 One-hot으로 집어넣기 |
| 특징 | - expressive power는 낮다. (graph의 구조에 대해서만 배운다.) - computation cost가 적다. - 그래프가 더 커져도 적용이 가능하다. (단순히 1만 추가하면 되므로) |
- expressive power는 높다 (각각의 node에 대해서 배울 수 있다.) - Computation cost가 크다. (one-hot vector 크기가 크므로) - 새로운 노드에는 적용이 불가능하다. (one-hot vector의 크기가 정해져 있으므로 노드가 늘어나면 새로 vector 크기를 정의해야 한다. |
| 설명 | 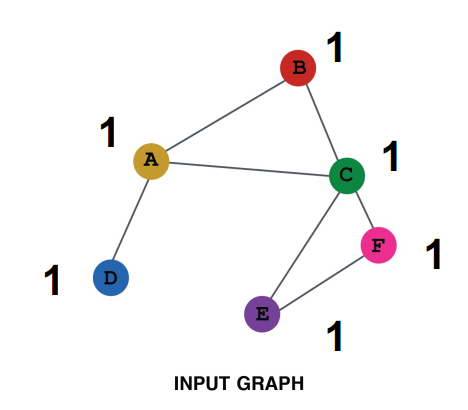 |
 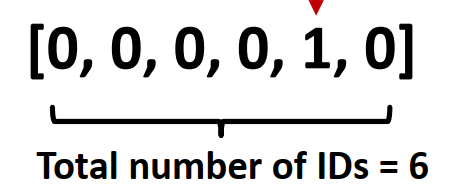 |
때로는 computation graph로는 배울 수 없는 feature들도 있다.
--> 예: 특정 길이의 cycle의 수
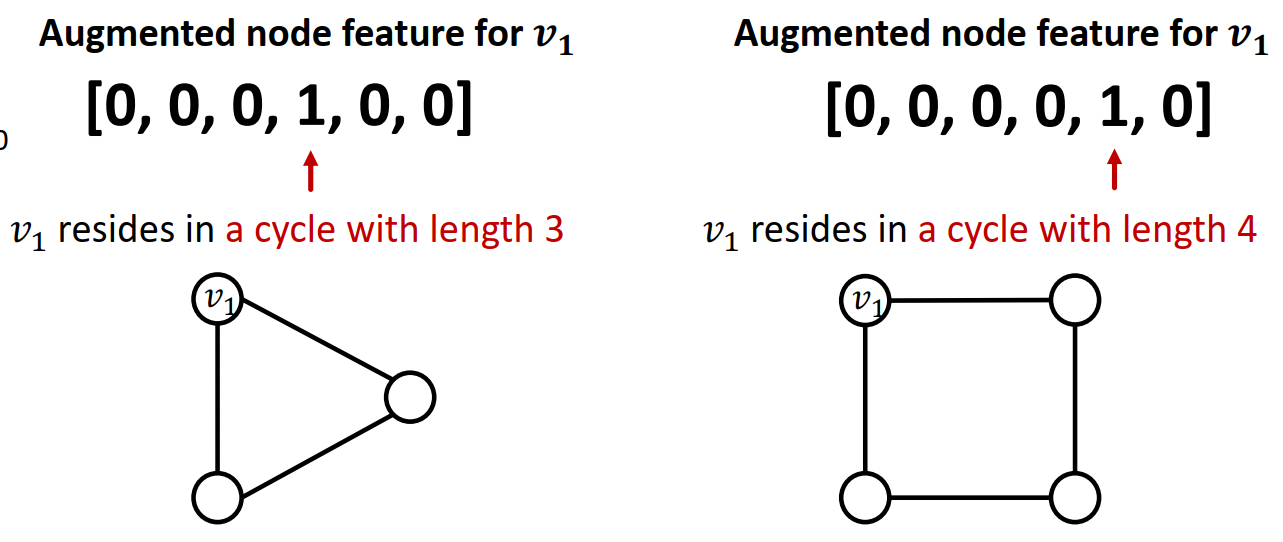
이러한 구조적인 정보는 넣어주면 더 좋다. (degree, clustering coefficient, pagerank, centraility)
* Structure augmentation
| Too Sparse할 경우 | Too Dense할 경우 |
| - biparate graph에서는 edge를 augment해서 한 논문을 같이 쓴 저자들을 묶어줄 수 있다. - 또는 모든 노드를 잇는 임의의 노드를 만들어서 아주 먼 노드를 이어줄 수 있다. |
- Neightbor Node를 샘플링 해야 한다. --> computation cost와 missing node로부터의 important message 간의 trade-off |
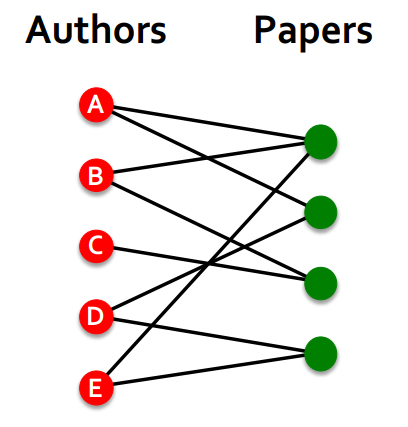 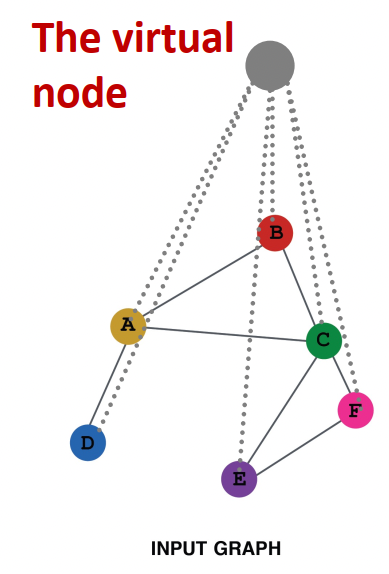 |
'배움 > Graph Representation Learning' 카테고리의 다른 글
| 9. How expressive are GNN? (0) | 2022.11.02 |
|---|---|
| 7. GNN (0) | 2022.10.13 |
| [CS224W] Lecture01 Introduction: Machine Learning for Graphs (0) | 2022.06.17 |