Heterogeneous Graph
기존 graph는 edge와 node로만 표현이 된다. G = (V, E)
Heterogeneous graph는 기존의 graph와는 달리 node와 edge(relation)의 type이 있다.
따라서 G = (V, E, R, T)로 표현된다.

특이한 점은 이제 edge가 (v_i, r, v_j), 즉, relation type이 추가되었다는 점이다.
(사실 relation의 방향성 또한 추가되었으니 유의하자.)
아래는 다양한 Heterogenous graph의 예시이다.

Relational GCN
Heterogenous에 GCN을 적용하려면 기존의 GCN을 어떻게 확장해야 할까?
기존의 GCN에서는 다음과 같이 GCN layer당 하나의 weight matrix를 공유해서 사용한다.
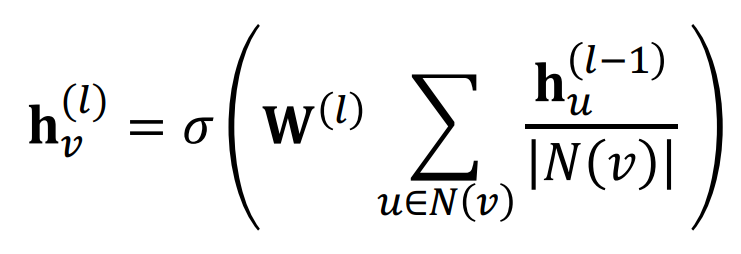

Relational GCN의 경우에는 relation type에 따라 다른 weight matrix를 사용한다.
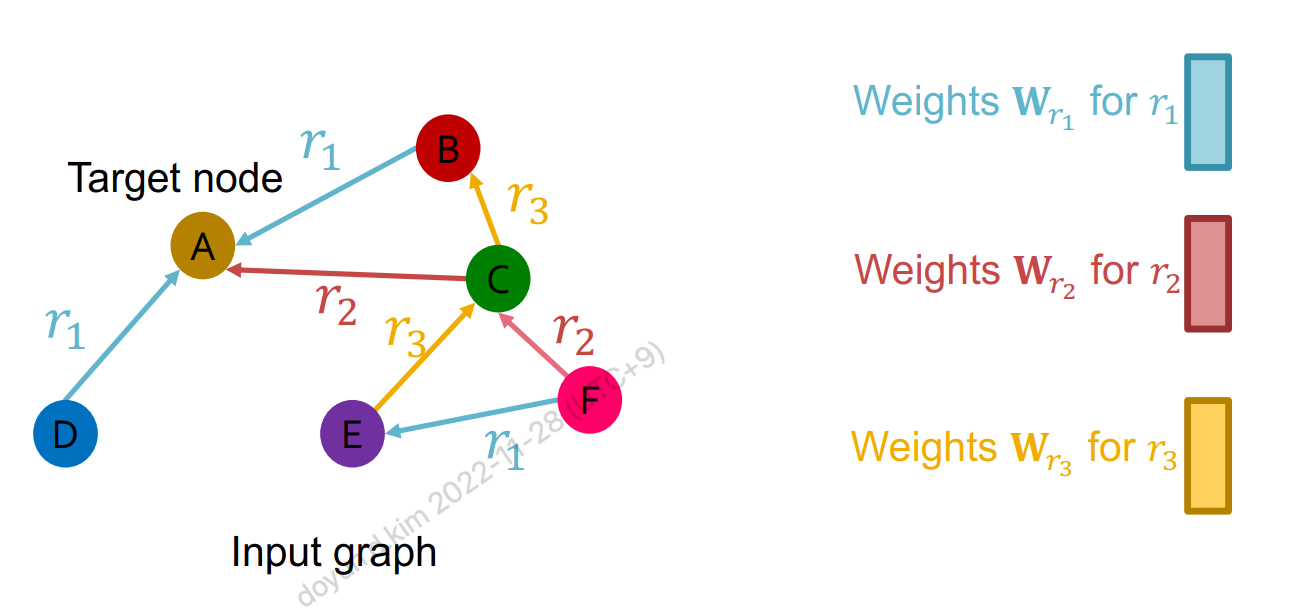

수식으로 표현하면 다음과 같다.

Relational GCN의 Scalability issue
Relational GCN에서 relation마다 서로 다른 weight matrix를 쓴다는 것을 알았다.
이 때 문제가 될 수 있는 것은 relation이 엄청나게 많은 graph도 있기 때문에 weight가 어마어마하게 많아진다는 것이다.
이를 해결하기 위해 2가지 방법이 쓰인다.
(1) Use Block dignoal matrices: 거대한 matrix 중 diagonal 근처 부분만 block으로 묶어서 사용. 멀리 있는 node끼리는 interaction하지 못한다는 단점이 있다.
(2) Basis Learning: Matrix를 다 새로 만드는 것이 아니라 Basis가 되는 vector들을 만들고 vector들의 조합으로 relation마다 weight matrix를 만든다.
Heterogenous graph에서의 Link Prediction
지난 link prediction에서 배웠듯이 message edge와 supervision edge를 나누고, 이를 또 training, validation, test edge로 바꿔서 차례대로 사용하는 edge들을 늘려가면서 training에 활용했다.
Heterogenous graph에서는 relation type별로 학습을 시켜야 하므로 이보다는 복잡하다.
(일단 당장 쓰이는 것이 아니므로 생략하도록 하겠다. 필요하면 슬라이드를 보자.)
Knowledge graph
Knowledge graph란 heterogenous graph의 한 예로 그래프 형태로 설명하는 것이다.
node들은 entity가 되고, node마다 type이 있다. 또한 node들끼리 다른 종류의 relationship으로 연결되어 있다.
다음은 knowledge graph의 예제로 medicine에 관한 예이다.
특정 약물이 어떤 질병에 효과가 있고, 어떤 부작용을 만드는지, 부작용은 어떤 단백질에 의해 일어나는지 등에 대해 그래프의 형태로 표현하고 있다.
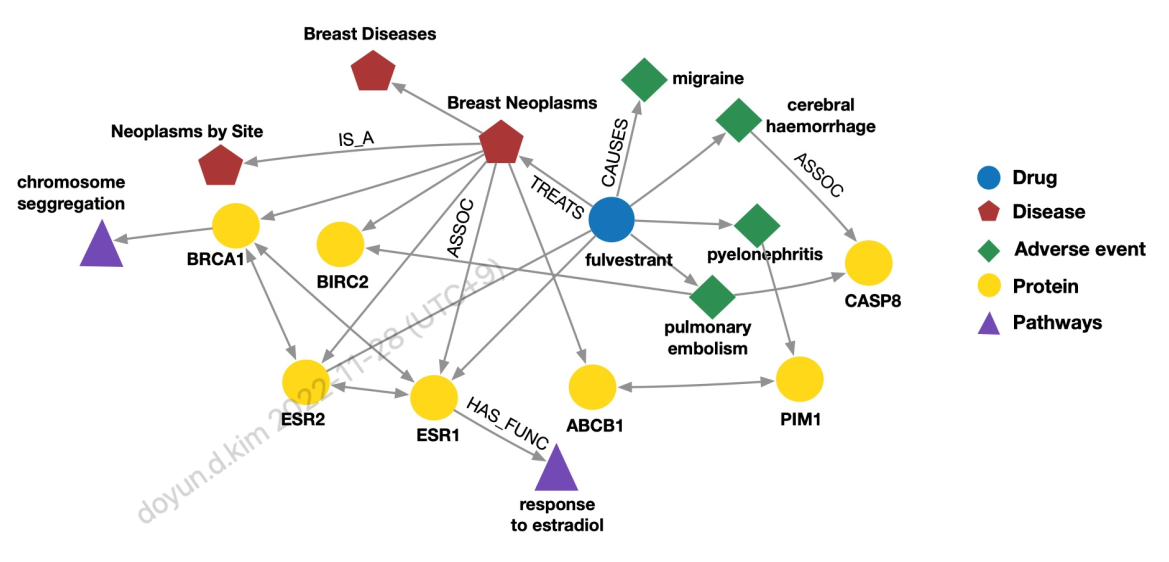
위와같이 Knowledge graph는 백만개 이상의 node와 edge 들로 구성되어 있어 크기가 크지만 많은 부분이 Incomplete이기 때문에 우리가 그러한 부분을 채우는 것이 주요 task 중 하나이다.
Knowledge graph Completion Task
(head, relation)이 주어졌을 때 어떻게 tail을 유추할 것인가?
-> (h, r)의 embedding을 구하면 (t)의 embedding과 유사한 값이 나와야 한다.
(1) 어떻게 embedding을 만들 것이고
(2) 어떻게 유사한지를 판단할 것인가?
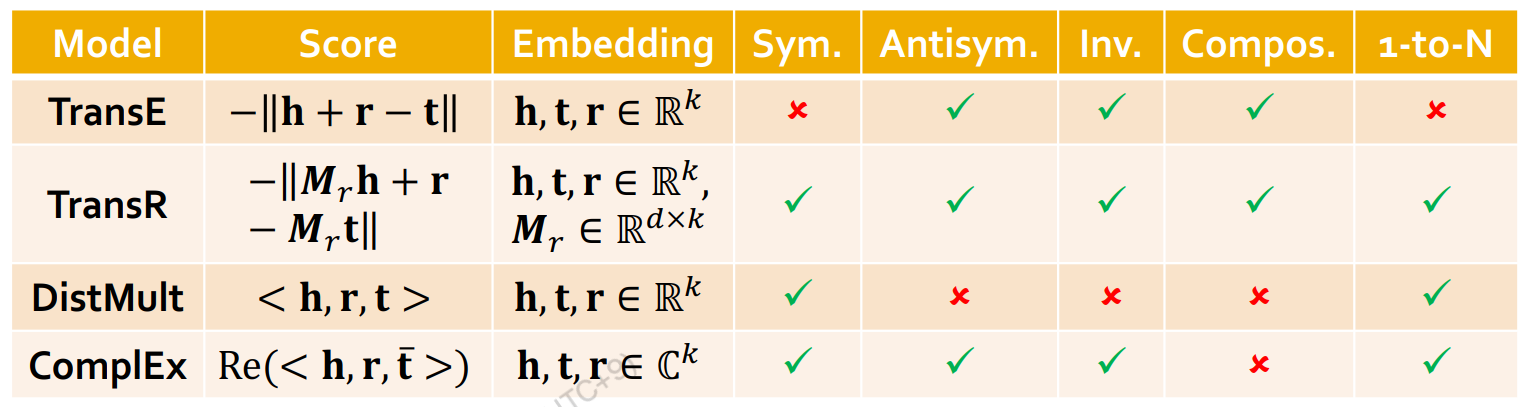
TransE: 벡터 h와 벡터 r의 합으로 t를 알아낸다.
TransR: Relation마다 벡터 h를 다른 임베딩 스페이스로 매핑해주는 M matrix가 존재하고 거기서 벡터의 합으로 나타낸다.
DisMult: h, r, t의 inner product를 가지고 계사한다.
ComplEx: DisMult인데 complex conjugate를 사용해서 확장.
다음과 같은 relation들을 표현할 수 있어야 expressiveness가 크다고 할 수 있다.

슬라이드에서는 각각을 그림으로 설명하는데 요약하면 다음과 같다.
'배움 > Reinforcement Learning' 카테고리의 다른 글
| 트랜스포머 (Transformer) 동작 원리 이해하기 (0) | 2022.11.03 |
|---|---|
| random seed 설정하기 (0) | 2022.09.24 |
| Policy invariance under reward transformation (0) | 2022.08.18 |