Decision Transformer를 배우기 위해 일단 Transformer부터 공부해 본다.
빛갓갓 동빈나 님이 체계적으로 잘 정리해주신 자료가 있어 덕분에 이해가 금방 되었다.
동빈나님이 설명하신 동영상에 seq2seq 모델이 나오는데 이에 관한 내용은 미리 다음 자료로 공부했었기 때문에 바로 이해할 수 있었다.
트랜스포머의 핵심 구조 익히기

트랜스포머는 일반적인 언어 모델처럼 Encoder와 Decoder로 구성되어 있다. Encoder는 여러 layer의 반복으로 이루어져 있고, Decoder 또한 여러 layer의 반복으로 이루어져 있다.
Encoder, Decoder를 이루고 있는 단위 layer에는 Self-attention layer라는 것이 들어가는데 이를 잠시 뒤에 자세히 살펴볼 것이다.
이 외에도 Positional Encoding이라는 것이 들어가는데 이것도 나중에 설명이 될 것이다.
언어 모델이기 때문에 Input을 Output으로 translate해준다.
이 때, Input은 문장이고, 문장을 구성하는 각각의 단어들을 Input Embedding layer를 통해 특정 길이의 Embedding으로 변환된다.
그리고 단위 레이어를 지나면서 인풋과 똑같은 크기의 아웃풋 데이터가 나오게 된다.
오른쪽 그림을 보면 알겠지만 Input이 그대로 Output으로 연결되는 Residual connection 또한 가지고 있다.
인코더의 마지막 레이어에서 나온 아웃풋을 모든 디코더 레이어에서 어텐션 메카니즘에 사용하기 위해 인풋으로 넣어준다.
Attention mechanism
트랜스포머를 설명할 때 attention mechanism을 빼놓을 수 없다.
attention mechanism이라는 것은 문장을 구성하고 있는 각 단어(혹은 토큰)들이 문장 내의 다른 단어와 얼마나 연관성이 있는지를 계산하여 가중치로 만들어서 각 단어들의 임베딩을 조합해서 최종 임베딩을 만드는 것이다.
예를 들면 I am a boy라는 문장이 있고, 이를 단어로 쪼개면 ["I", "am", "a", "boy"]이다.
"I"라는 단어의 임베딩 출력을 구하기 위해서는 I와 다른 단어와의 유사성을 찾게 되는데 이 유사성이 [0.7, 0.05, 0.05, 0.2]로 나온다고 하면 임베딩 출력은 각 단어들의 임베딩에 위의 유사성 숫자를 가중치로 곱해준 값들의 합이 되게 된다.
트랜스포머는 이를 Query (Q), Key (K), Value (V)라는 개념으로 설명한다.
하나의 Q에 해당하는 임베딩을 찾기 위해 각 K와의 유사성을 MatMul을 이용해서 체크한다.
그리고 이를 통해 가중치 (energy라고 표현하더라)를 구하고 가중치만큼 Value를 더해줘서 최종적인 Q의 임베딩을 만들어 낸다.
attention mechanism은 seq2seq 모델에도 나오는데 트랜스포머에서는 "self-attention"이라는 것이 중요하다.
즉, attention을 만들 때 자기 정보만 가지고 만든다는 것이다.
seq2seq 모델을 기억해보면 decoder의 attention 정보를 만들기 위해 encoder의 정보를 활용해서 가중치를 만든다.
트랜스포머의 인코더에서는 Q, K, V가 같은 문장에서 다 나오게 된다.
V, K, Q를 직접 쓰는 것이 아니라 MLP layer를 거쳐서 만들어낸 값을 활용하는데, h개 만큼의 MLP layer를 병렬로 사용해서 다양한 attention을 만들고 임베딩을 만들어서 이를 조합해서 사용한다.
좀더 과정을 자세히 살펴보면 다음과 같다.
일단 한 단어의 임베딩을 가지고 Query, Key, Value를 다 만들 것이다.
나중에 여러 head를 concat해서 사용할 것이기 때문에 embedding의 길이를 head의 개수로 나눈 vector 길이로 나오게 된다.
그렇게 만들어진 Q, K, V를 가지고 Attention을 구한다.
Q,K는 Matrix multiplication을 통해 (dot product처럼) 유사도를 구하고 거기에 Value를 곱한다.
dk로 Normalize하는 이유는 backprob을 위해 softmax의 gradient가 큰 지점에 위치시키기 위함이다.
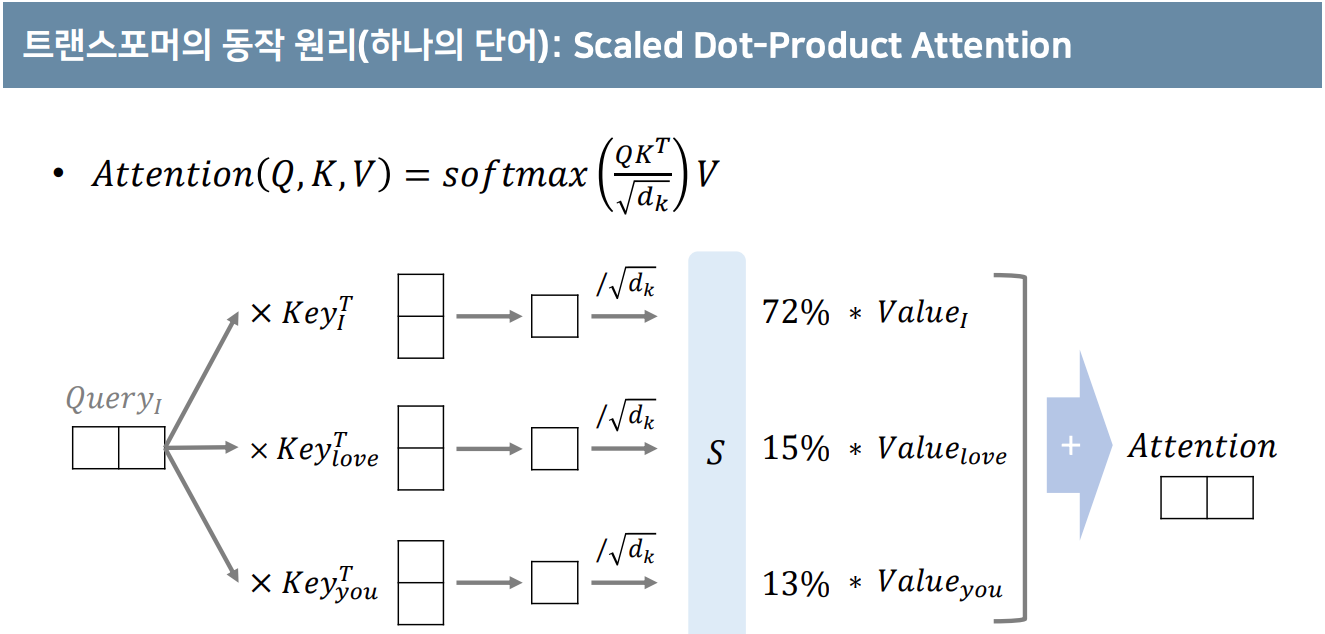
위에서는 하나의 단어에 대해서만 Attention을 만들었지만 사실 여러개의 단어를 동시에 만들게 된다.


embedding matrix와 attention energy matrix를 곱해서 최종 attention을 구해주게 되는데 임의로 attention energy matrix에 마스크 행렬을 곱해서 특정 단어와의 연관성을 없앨 수도 있다.
(이는 Decoder에서 쓰이게 되는데 Decoder에서는 단어를 전부 참조하는 것이 아니라 이미 나온 단어들만 참조하게 만들고 싶기 때문에 미래의 단어들을 참조하는 attention은 마스킹하게 된다.)


위에서 말했듯이 Multi-head attention이기 때문에 각 head에서 나온 attention들을 concat하고 MLP를 통해서 최종 출력을 만든다.


Positional Encoding
트랜스포머는 RNN이나 LSTM을 활용하는 Seq2Seq 모델처럼 단어를 순차적으로 받는 것이 아니라 문장이 한꺼번에 들어간다.
따라서 단어의 위치 정보를 넣어줘야 하는데 이를 하기 위해 Positional Encoding이라는 것을 활용한다.
식은 다음과 같다.
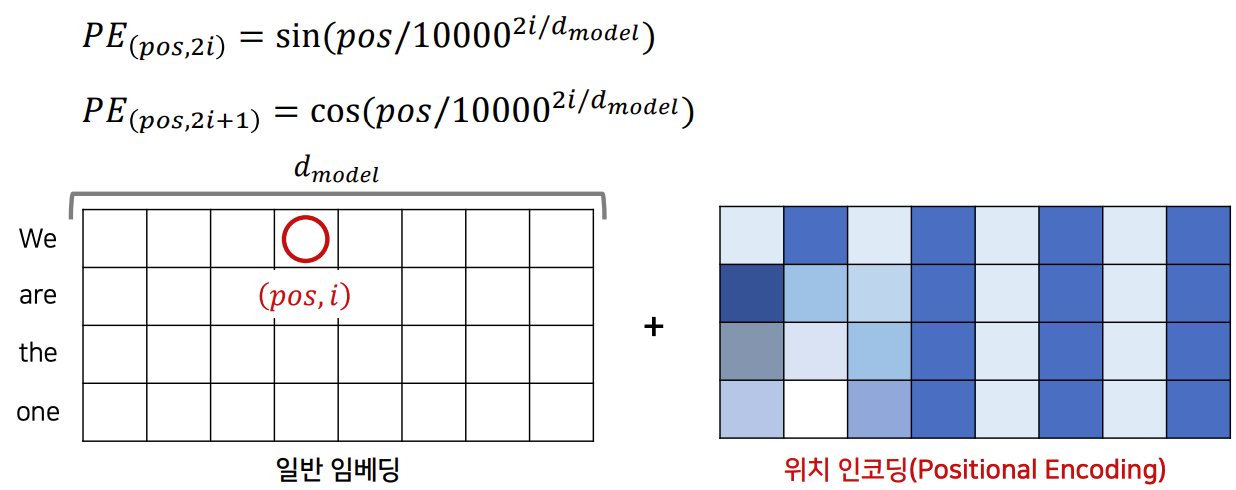
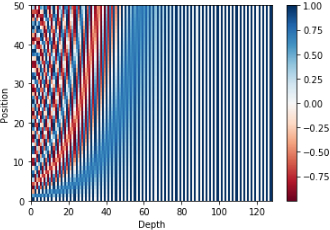
임베딩의 size와 position을 늘리면 다음과 같이 나온다.
'배움 > Reinforcement Learning' 카테고리의 다른 글
| 10. Knowledge Graph (0) | 2022.11.29 |
|---|---|
| random seed 설정하기 (0) | 2022.09.24 |
| Policy invariance under reward transformation (0) | 2022.08.18 |