이 챕터에서는 GNN이 그래프 안의 노드들을 얼마나 잘 구별하여 노드 임베딩을 만들어줄 수 있는지 이론적으로 알아보는 시간이다.
이 챕터를 다 배우게 되면 어떤 GNN 구조가 가장 expressive power가 좋은지 알게 될 것이다.
GNN은 어떻게 노드를 구별할까?
node들에 따로 id 같은 feature가 없다고 할 때 graph structure만 가지고 노드들을 얼마나 잘 구별할 수 있을까?
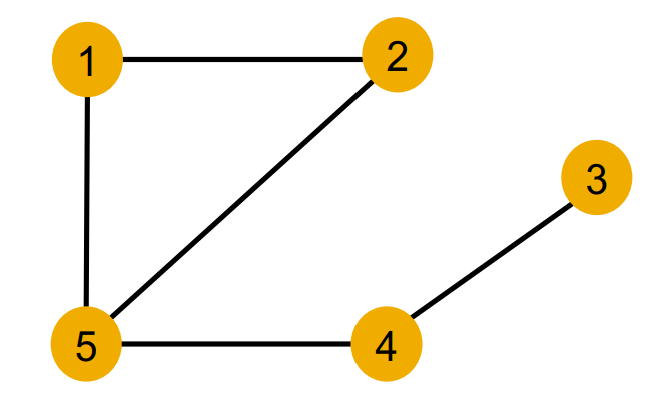
위와 같은 구조를 보면 1,2,3,4,5는 노드 피쳐가 없다. 즉, 구별할 수 없는 노드이기 때문에 노드가 그래프 내에 어디에 달려있는지 그 위치 만으로 구별해야 한다.
직관적으로 봤을 때, 1번 노드와 2번 노드는 같게 취급이 될 것이라는 걸 알 수 있다.
노드가 구별하기 위해서는 각 노드별로 만들어지는 computational graph의 구조가 달라야 한다.
1번, 2번 노드의 computational graph를 아래와 같이 그렸을 때 둘의 구조가 정확히 일치하는 것을 알 수 있다.
(노드 번호가 다른 것은 ID가 노드 피쳐로 들어가지 않았으므로 실제로는 구별할 수 없다.)

아래와 같이 모든 노드들에 대해 computational graph(rooted subgraph structure)를 그려봤을 때 서로 다른 computational graph를 가진 노드들만이 서로 다른 임베딩을 갖게 된다.
결국 GNN의 역할은 computational graph를 임베딩으로 매핑하게 되는데,
다른 computational graph는 다른 embedding이 나오기 위해서는 매핑이 "injective" 해야 한다.
그리고 매핑이 injective하기 위해서는 computational graph의 내부 과정인 neighbor aggregation 또한 injective 해야 한다.
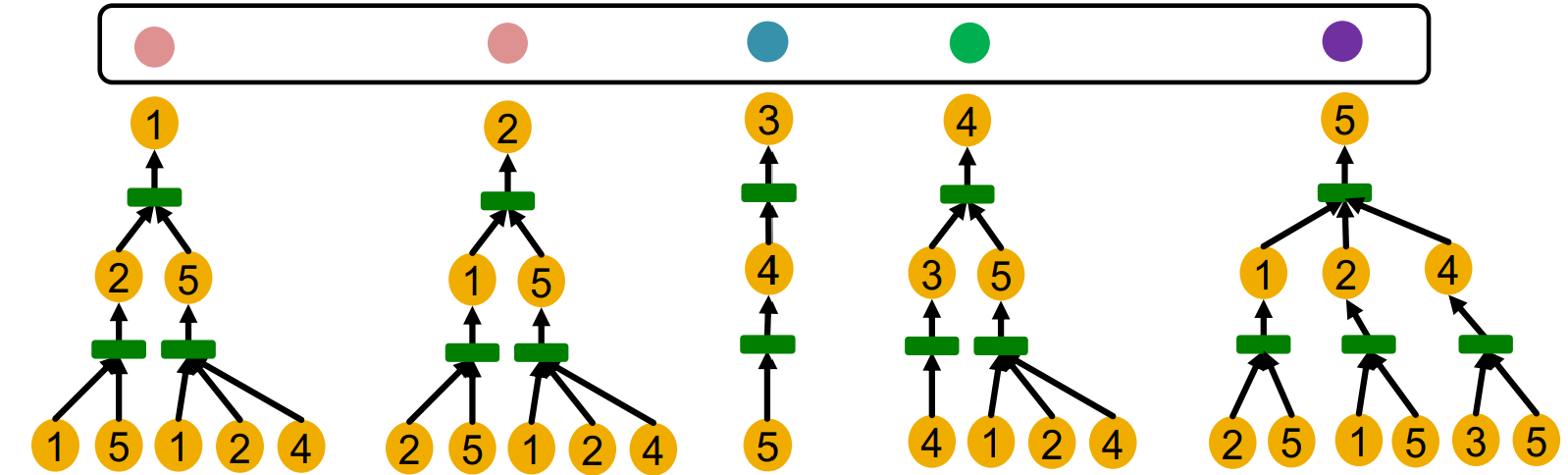
GNN이 expressive하지 못할 때
위에서 GNN이 expressive하기 위해서는 neighbor aggregation이 injective해야 한다고 했다.
그렇다면 과연 어떤 neighbor aggregation이 좋을까?
(우리가 하는 neightbor aggregation의 대상은 multi-set이라고 할 수 있다. 여기서 multi-set은 같은 item이 반복될 수 있는 set을 말한다)
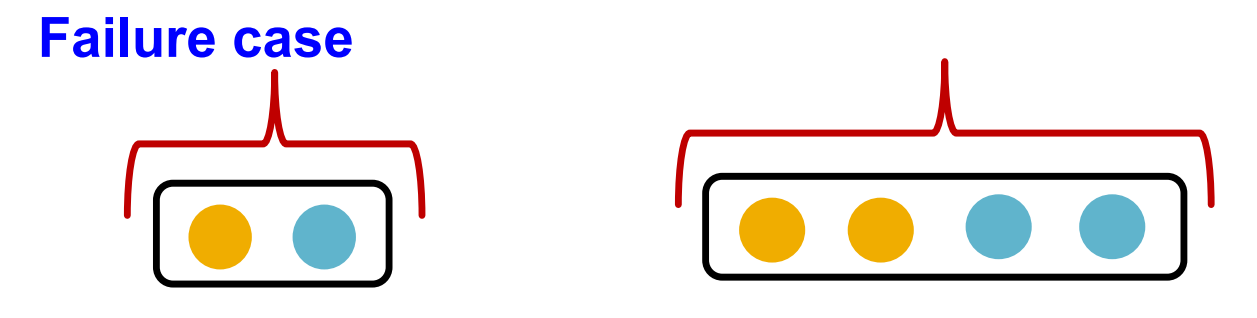
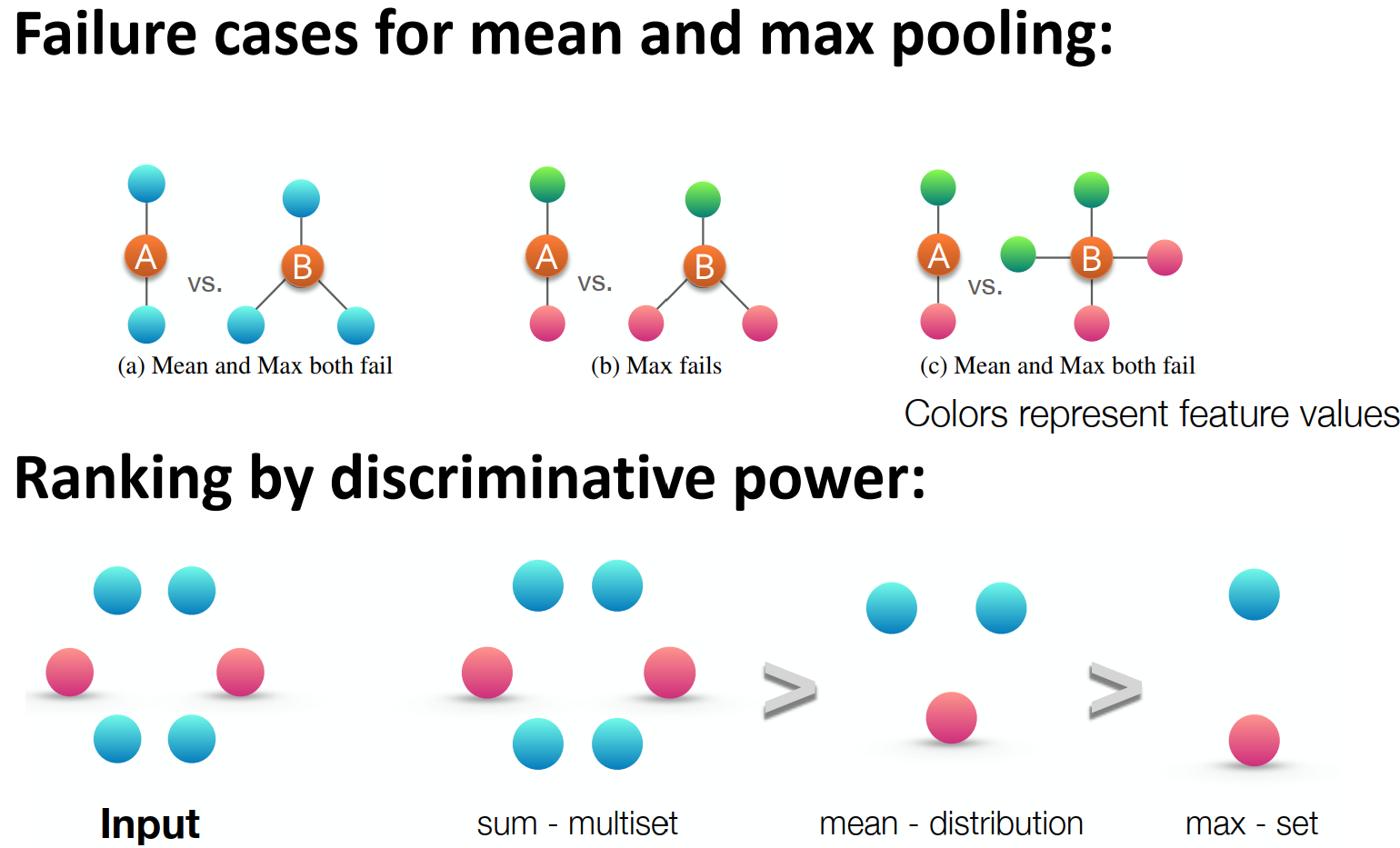
Mean pooling failure case (GCN)
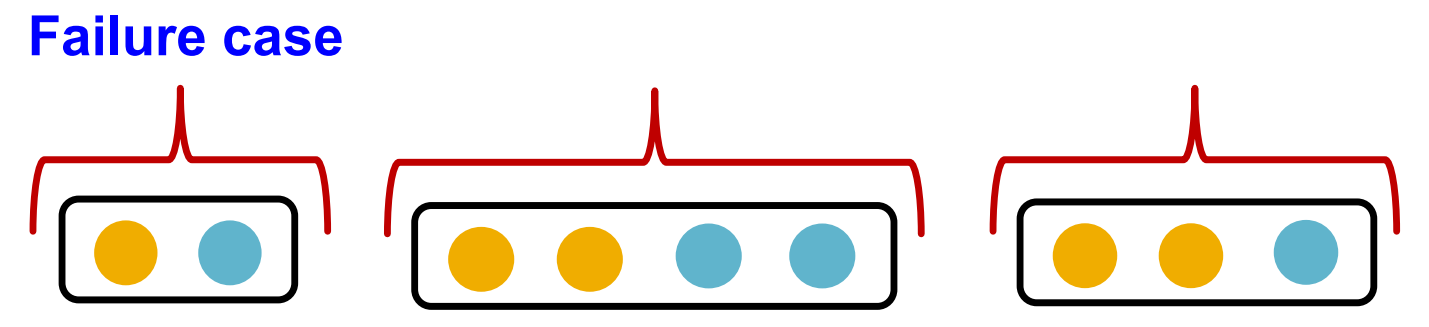
Max pooling failure case (GraphSAGE)
The most expressive GNN - Graph Isomorphism Network (GIN)
GIN을 설명하기에 앞서 다음과 같은 두 개념을 알아두자.
Injective multi-set function
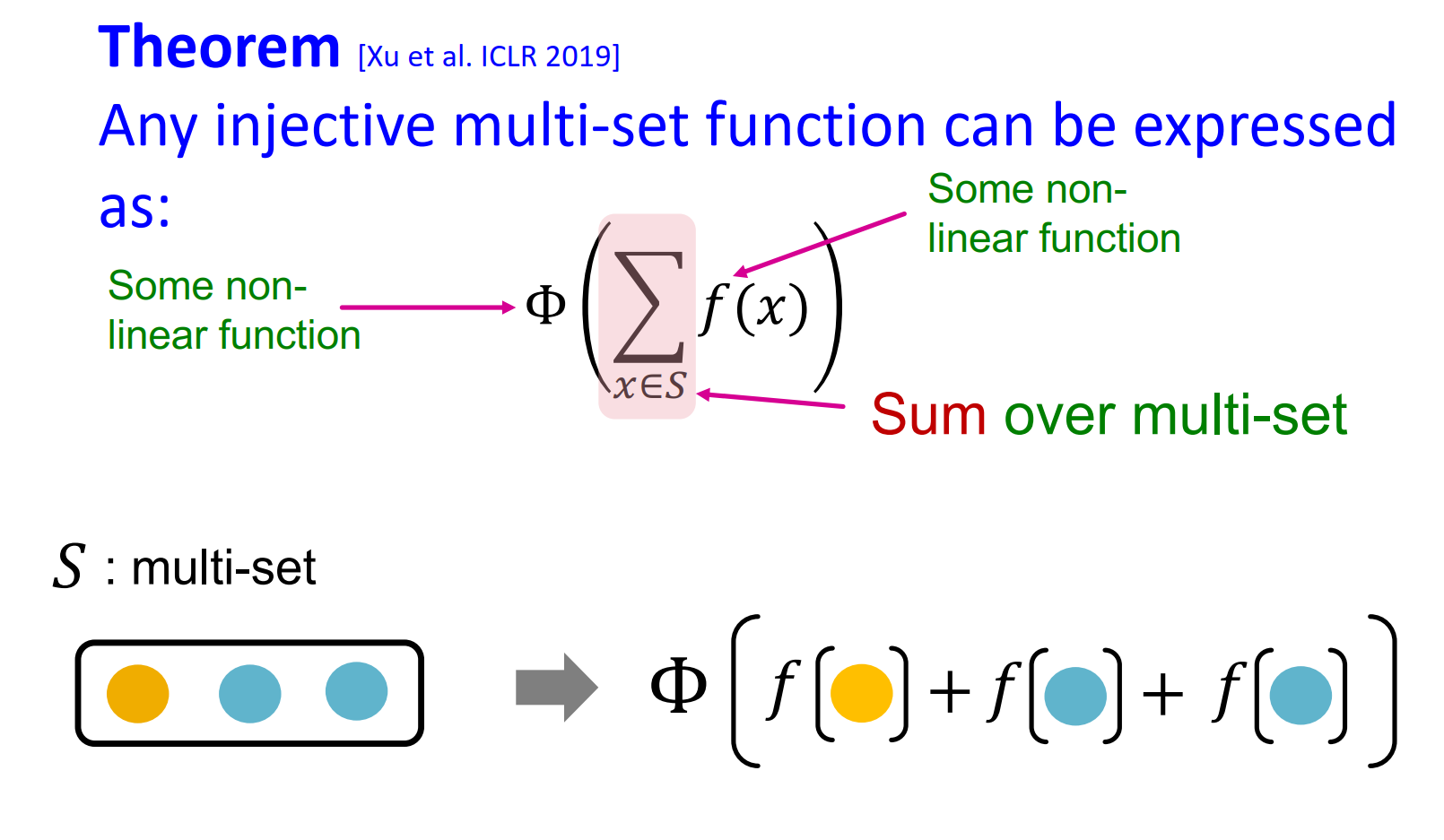
Universal Approximation Theorem
1개의 hidden layer를 가진 MLP가 충분히 크면 어떤 continuous function이던 임의의 정확도로 근사할 수 있다.
위 두개의 theorem에 따라 Injective한 aggregation function을 만들면 다음과 같다.
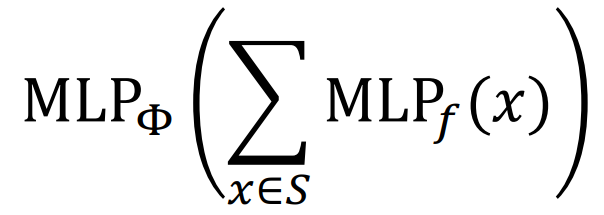
즉, injective한 동시에 MLP 파트들을 잘 학습시켜서 뒤이어 나오는 downstream task 또한 잘 수행될 수 있도록 학습시킬 수 있다.
GIN과 WL Graph Kernel의 유사성
우리는 챕터2에서 그래프를 구별할 수 있는 WL Graph Kernel에 대해 배웠다.
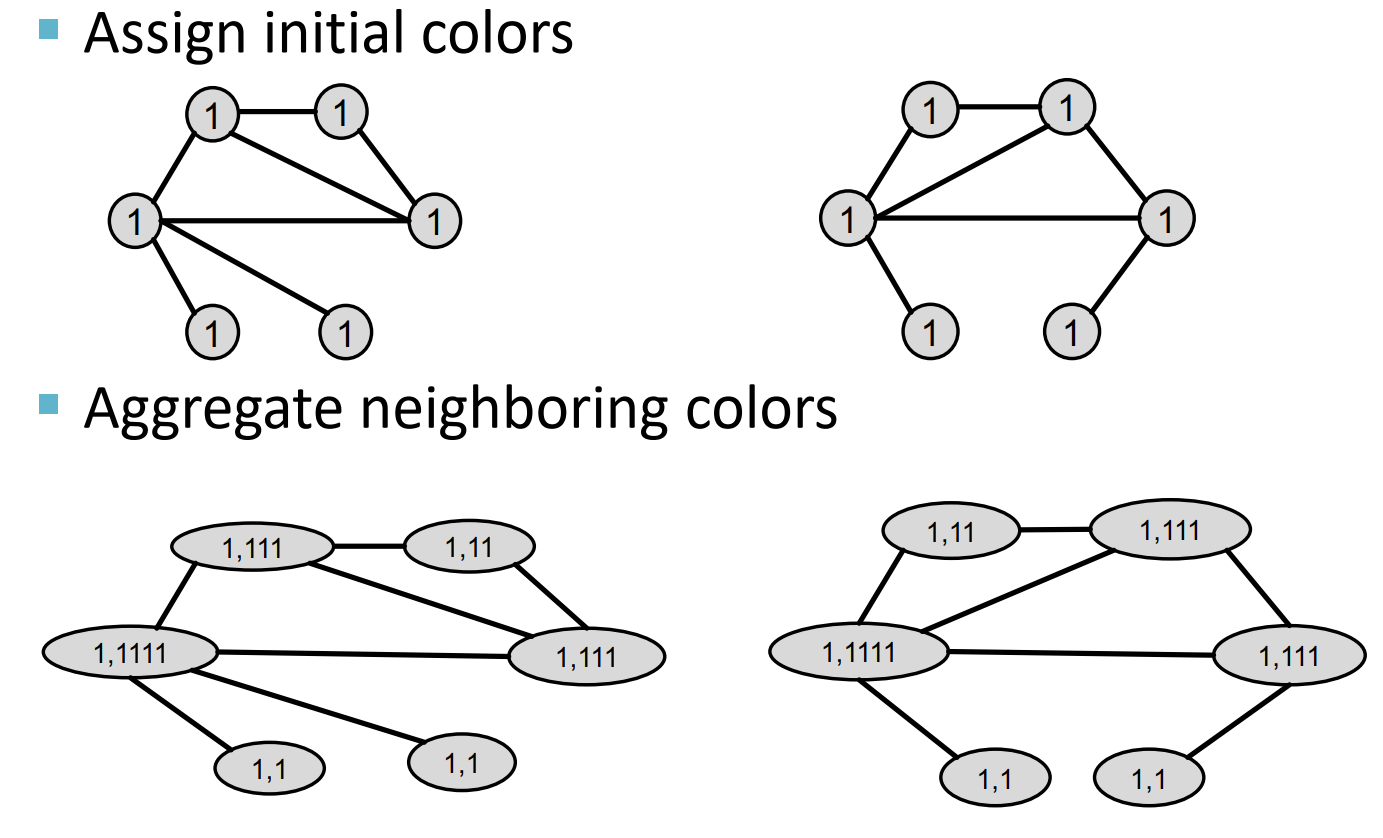

WL Graph Kernel도 주변 노드에서 정보를 합친 뒤 (sum) Hash를 통해 새로운 ID로 매핑한다.
이는 GIN이 하는 일과 굉장히 유사한데 K-step의 GIN operation을 반복하면 K-hop neighborhood 구조를 summarize하는 것과 같은 효과이다.

Pooling의 expressive power 순위
1. Sum (GIN) - multiset 구별 가능
2. Mean (GCN) - distribution 구별 가능
3. Max (GraphSAGE) - set 구별 가능
'배움 > Graph Representation Learning' 카테고리의 다른 글
| 8. GNN Training (2) | 2022.10.30 |
|---|---|
| 7. GNN (0) | 2022.10.13 |
| [CS224W] Lecture01 Introduction: Machine Learning for Graphs (0) | 2022.06.17 |










