Classification Tree
Decision Tree(결정 트리)란?
Decision Tree는 supervised learning 중의 하나로 연속적인 질문을 통해서 예측하는 모델이다.
이 때, 최종적으로 분류를 예측하면 Classification Tree, 값을 예측하면 Regression Tree가 된다.
Tree라는 이름에 걸맞게 root node부터 시작해서 가지(branch)를 치며 여러가지 node로 나뉘어 지게 된다.
마지막에 예측을 하는 node는 leaf라고 부른다.
이 때, 각 node에는 각 변수에 관한 질문들이 있고, 이에 대한 대답을 통해 branch로 나뉘어지게 된다.
목표는 각 node의 질문을 잘 설정해서 마지막 분류 혹은 값의 예측이 실제 분류나 값과 일치하거나 에러가 적도록 만들어야 한다.

위의 표에서 보이는 바와 같이 세가지 변수를 가지고 Cool As Ice라는 제품을 좋아하는지 분류하는 모델을 만드는 과정을 살펴보자.
1. 어떤 변수를 가지고 root node를 만들어야 할까?
가장 먼저 하는 질문이므로 가장 결과를 잘 분류할 수 있도록 변수를 설정해야 할 것이다.
먼저 "Loves Popcorn"이라는 항목과 "Loves Soda"을 가지고 분류를 한다고 생각해보자.
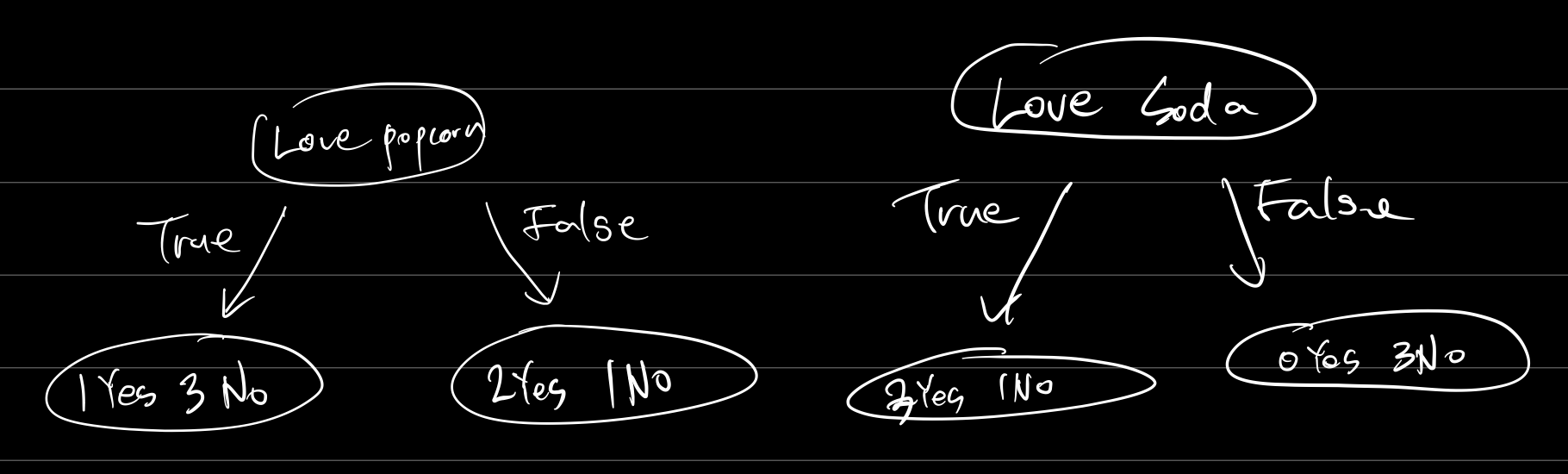
과연 둘 중에 누가 분류를 더 잘한 것일까?
직관적으로 "Love Soda?"라는 질문을 가지고 했을 때 좀 더 분류를 뚜렷하게 하는 것 같다.
하지만 이걸 어떻게 수치화할까?
이 때 우리는 Gini Impurity라는 방법을 사용하는데 Gini Impurity가 낮은 쪽으로 (즉, pure하게 나뉠 수 있도록) 가지를 나눠야 한다.
Gini Impurity 계산하기
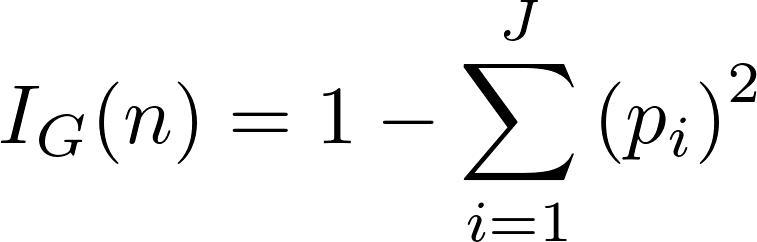
Leaf node에서 Gini Impurity는 1에서 각 분류의 비율을 제곱해서 빼면 된다.
맨 왼쪽의 경우 yes는 1/4, no는 3/4이므로
$$ 1 - (\frac{1}{4})^2 - (\frac{3}{4})^2 = 0.375 $$
Leaf node가 아닌 node에서는 child node들의 Gini Impurity를 데이터의 비율대로 더해주면 된다.
Love Popcorn?의 경우를 살펴보면
$$ \frac{4}{7}(1 - (\frac{1}{4})^2 - (\frac{3}{4})^2) + \frac{3}{7}(1 - (\frac{2}{3})^2 - (\frac{1}{3})^2) = 0.405 $$
Love Soda?의 경우를 살펴보면
$$ \frac{4}{7}(1 - (\frac{3}{4})^2 - (\frac{1}{4})^2) + \frac{3}{7}(1 - (\frac{3}{3})^2 - (\frac{0}{3})^2) = 0.214 $$
위의 수식과 같이 "Love Popcorn?"을 사용하면 Gini Impurity는 0.405, "Love Soda?"는 0.214라는 값이 나온다.
따라서 우리의 직관과 마찬가지로 "Love Soda?"를 가지고 분류하는 것이 더 좋다.
Q2. 그렇다면 카테고리가 아닌 값으로 되어 있는 변수는 어떻게 활용할까?
Age 같은 경우에는 카테고리가 아닌 값으로 되어 있기 때문에 분류에 활용하기 위해서는 경계값(threshold)를 정해주어야 한다.
즉, Age를 오름차순으로 정렬했을 때, 그 중간값을 가지고 노드를 만들게 된다.
예를 들면 7과 12의 중간값인 (Age > 9.5?)라는 노드를 만들어서 가지를 만들게 된다.
그러면 카테고리 값과 마찬가지로 Gini Impurity를 구할 수 있을 것이다.
데이터가 N개 있으면 N-1개의 중간값을 만들 수 있는데 이를 전부 체크해서 최소 Gini Impurity를 만드는 중간값을 경계값으로 정한다.
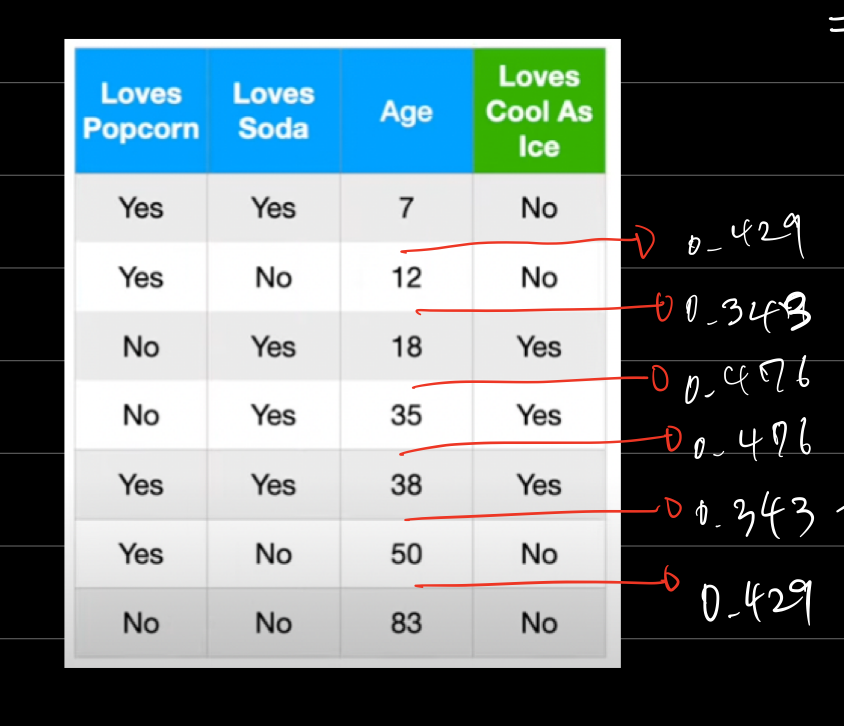
최종적으로 세 변수로 만든 Node 중 Gini Impurity가 가장 낮은 것을 골라 root node를 만든다.
위의 예제에서는 Love Popcorn? = 0.405, Love Soda? = 0.213, Age > 15? = 0.343 이므로 Love Soda?를 root node로 사용하면 된다.
root node 이후에는 어떻게 해야할까?
root node 이후에도 이와 같은 방식으로 계속 가지를 만들어 내려가면 된다.
노드 하나당 가지를 몇개로 할 것인지(보통 2개이다), root로부터 얼마만큼 깊게 가지를 내릴 것인지 등은 하이퍼파라미터로 정할 수 있다.










